
Managing Slack Join – Slack Engineering

Slack Connect, AKA shared channels, permits communication between completely different Slack workspaces, through channels shared by taking part organizations. Slack Join has existed for a couple of years now, and the sheer quantity of channels and exterior connections has elevated considerably for the reason that launch. The elevated quantity launched scaling issues, but additionally highlighted that not all exterior connections are the identical, and that our clients have completely different relationships with their companions. We would have liked a system that allowed us to customise every connection, whereas additionally permitting admins to simply handle the variety of ever-growing connections and related channels. The present configuration system didn’t enable customization by exterior connections, and admin instruments weren’t constructed to deal with the ever-growing scale. On this submit, we’ll discuss how we solved these challenges on the backend (the frontend implementation is its personal story, and deserves a separate weblog entry).
Our first try at per-connection configuration
Slack Join was constructed with safety in thoughts. With the intention to set up a shared channel between two organizations, an exterior consumer should first settle for a Slack Join invitation, then the admins on each sides should approve the brand new shared channel, and solely after these steps can the communication start. This works high quality for one-off channels between two corporations, however the guide approval delay can turn out to be a nuisance—and probably a barrier—whenever you want new channels created day by day by many customers in your group. This additionally locations a heavy burden on admins to overview and approve an ever rising variety of channels they could lack the context round.
The answer was so as to add the power for admins to automate the approval course of. We created a MySQL desk which represented a connection between two groups. Crew A may authorize computerized approvals for requests from workforce B, and vice versa. We would have liked a number of database columns to symbolize how the automated approvals ought to work. Slack Admins acquired a dashboard the place they may go in and configure this setting. This method labored properly, and additional accelerated the expansion of Slack Join. However quickly after we realized we would have liked to customise extra than simply approvals.
Normal answer to managing per-connection configuration
Along with auto-approvals, we additionally wanted connection-level settings to manage restrictions on file uploads in Slack Join channels and the power to restrict seen consumer profile fields for exterior customers. In the long run, the plan was to customise the Slack Join expertise on a partner-by-partner stage. The potential for including a brand new database desk per setting was not interesting. We would have liked an extensible answer that would accommodate including new settings with out requiring infrastructure modifications. The principle necessities had been assist for built-in default configuration, a team-wide configuration, and the power to set per-connection configurations. A connection/partner-level configuration permits for a particular setting to be utilized on a goal companion. Default configuration is one thing that comes out of the field, and is the setting which will probably be utilized when the admin doesn’t customise something. Org/team-level configuration permits admins to override the default out-of-the-box setting, and will probably be utilized in circumstances when a connection-level setting doesn’t exist. The diagram beneath describes the sequence through which settings are evaluated and utilized.

We borrowed from the database schema of the approvals desk, and created a brand new desk with supply and goal workforce IDs, and a payload column. The desk regarded like this:
CREATE TABLE `slack_connect_prefs` (
`team_id` bigint unsigned NOT NULL,
`target_team_id` bigint unsigned NOT NULL,
`prefs` mediumblob NOT NULL,
`date_create` int unsigned NOT NULL,
`date_update` int unsigned NOT NULL,
PRIMARY KEY (`team_id`,`target_team_id`),
KEY `target_team_id` (`target_team_id`)
)We modeled org-level configuration by setting the goal workforce as 0. Associate-level configuration had the workforce ID of the connection. We created an index on supply and vacation spot workforce IDs which allowed us to effectively question the desk. The desk was additionally partitioned by supply workforce ID, which suggests all rows belonging to the supply workforce lived on the identical shard. This can be a frequent sharding technique at Slack which permits us to scale horizontally. As a substitute of utilizing a set of columns to mannequin every setting, we opted to make use of a single column with a Protobuf blob because the payload. This allowed us to have complicated knowledge sorts per every setting, whereas additionally lowering DB storage wants and avoiding the 1,017 columns-per-table restriction. Right here at Slack now we have present tooling for dealing with Protobuf messages, which makes it straightforward to function on the blob columns inside the applying code. The default configuration was applied in software code by primarily hardcoding values.
Now that we had a strong storage layer, we needed to construct the applying layer. We utilized an present Slack sample of making a Retailer class to deal with all database interactions with a given desk or a associated set of tables. A retailer is an analogous idea to a service in a microservices structure. We created a SlackConnectPrefsStore class whose predominant job was to offer shoppers a easy API for interacting with Slack Join prefs. Beneath the hood, this concerned studying from the database or cache, operating validation logic, sending occasions and audit logs, and parsing Protobufs. The Protobuf definition regarded like this, with the SlackConnectPrefs message being the container for all subsequent prefs:
message SlackConnectPrefs {
PrefOne pref_one = 1;
PrefTwo pref_two = 2;
...
}
message PrefOne {
bool worth = 1;
}Our Retailer class helps get, set, take away, and record operations, and makes use of Memcached to scale back database calls when attainable. The preliminary Retailer implementation was tightly coupled to the prefs it was working on. For instance, some prefs wanted to ship fanout messages to shoppers a few pref state change, so inside our set operate we had a block like this:
operate set(PrefContainer container) {
...
if (container.pref_one != null) {
send_fanout_message(container.pref_one);
}
...
}We had code blocks to deal with transformation and validation for every pref, to bust cache, and for error dealing with. This sample was unsustainable: the code grew very lengthy, and making modifications to a retailer operate for a single pref carried a threat of breaking all prefs. The shop design wanted to evolve to have isolation between prefs, and to be simply and safely extendable for brand new prefs.
Evolution of the applying layer
We had two competing concepts to deal with the isolation and extendability issues. One choice was to make use of code era to deal with the transformation, and presumably the validation duties as properly. The opposite choice was to create wrapper lessons round every pref Protobuf message and have the shop delegate duties to those lessons. After some dialogue and design doc evaluations, our workforce determined to go together with the wrapper class choice. Whereas code era has in depth tooling, every pref was too completely different to specify as a code-generated template, and would nonetheless require builders to customise sure features associated to the pref.
We modeled our class construction to mirror the Protobuf definition. We created a container class which was a registry of all supported prefs and delegated duties to them. We created an summary pref class with some frequent summary strategies like rework, isValid, and migrate. Lastly, particular person prefs would inherit from the summary pref class and implement any required strategies. The container class was created from a top-level Protobuf message, SlackConnectPrefs within the instance above. The container then orchestrated creation of particular person pref lessons—PrefOne within the instance above—by taking the related Protobuf sub messages and passing them to their respective lessons. Every pref class knew tips on how to deal with its personal sub message. The extensibility downside was solved, as a result of every new pref needed to implement its personal class. The implementer didn’t have to have any data of how the shop works and will deal with coding up the summary strategies. To make that job even simpler, our workforce invested in creating detailed documentation (and nonetheless continues to replace it because the code evolves). Our intention is to make the Slack Join prefs system self-serve, with little-to-no involvement from our workforce.
The ultimate software layer regarded one thing like this:
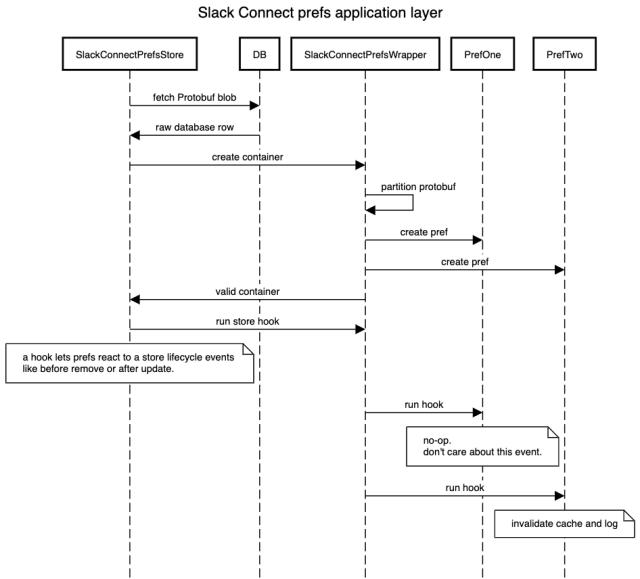
The isolation downside was partially solved by this design, however we would have liked an additional layer of safety to make sure that an exception in a single pref didn’t intrude with others. This was dealt with on the container stage. For instance, when the Retailer wanted to test that every one messages within the Protobuf are legitimate, it could name containers isValid methodology. The container would then iterate by means of every pref and name the prefs isValid methodology, any exceptions could be caught and logged.
Simplifying administration at scale
Up to now, now we have a strong database layer and a versatile software layer which will be plugged into locations the place we have to eat pref configuration. On the admin facet, now we have some dashboards which present details about exterior connections, pending invites, and approvals. The APIs behind the dashboards had a standard sample of studying rows from a number of database tables, combining them collectively, after which making use of search, type, and filtering based mostly on API request parameters.
This method labored high quality for a number of thousand exterior connections, however the latency saved creeping up, and the variety of timeouts—and consequently triggered alerts—saved growing. The admin dashboard APIs had been making too many database requests, and the ensuing knowledge units had been unbounded within the variety of rows. Including caching helped to a level, however because the variety of connections saved going up, the present sorting, filtering, and search performance was not assembly consumer wants. Efficiency points and missing performance led us to think about a special sample for admin API handlers.
We rapidly dominated out combining a number of database calls right into a single SQL assertion with many joins. Whereas database-level be a part of would have decreased the variety of particular person queries, the price of doing a be a part of over partitioned tables is excessive, and one thing we typically keep away from at Slack. The database partitioning and efficiency of queries is its personal subject, and is described in additional element in Scaling Datastores at Slack with Vitess.
Our different choice was to denormalize the information right into a single knowledge retailer and question it. The controversy was centered round which know-how to make use of, with MySQL and Solr being the 2 choices. Each of those choices would require a mechanism to maintain the denormalized view of the information in sync with the supply of fact knowledge. Solr required that we construct an offline job which may rebuild the search index from scratch. MySQL assured studying the information instantly after a write, whereas Solr had a 5 second delay. Alternatively, Solr paperwork are absolutely listed, which provides us environment friendly sorting, filtering, and textual content search capabilities with out the necessity to manually add indexes to assist a given question. Solr additionally presents a straightforward question mechanism for array-based fields which aren’t supported in MySQL. Including new fields to a Solr doc is less complicated than including a brand new column to a database desk, ought to we ever have to broaden the information set we function on. After some inside discussions, we opted to go together with the Solr choice for its search capabilities. Ultimately it proved to be the correct alternative: we now have a dashboard which may scale to deal with thousands and thousands of exterior connections, whereas offering quick text-based looking out and filtering. We additionally took benefit of the power to dynamically add fields to a Solr doc, which allowed for all newly created Slack Join settings to be mechanically listed in Solr.
What is going to we construct subsequent?
The power to have configuration per exterior connection has opened a variety of doorways for us. Our present permission and coverage controls should not connection conscious. Making permissions like WhoCanCreateSlackConnectChannels connection-aware can unlock a variety of progress potential. Our scaling work isn’t carried out and we’ll proceed to have looming challenges to beat relating to the variety of related groups and the variety of related exterior customers.
For those who discovered these technical challenges attention-grabbing, you can too join our network of employees at Slack!


/cdn.vox-cdn.com/uploads/chorus_asset/file/24371483/236494_Mac_mini__2023__AKrales_0066.jpg)

